Private AI
Private AI for sensitive data. Your data stays where you want it.
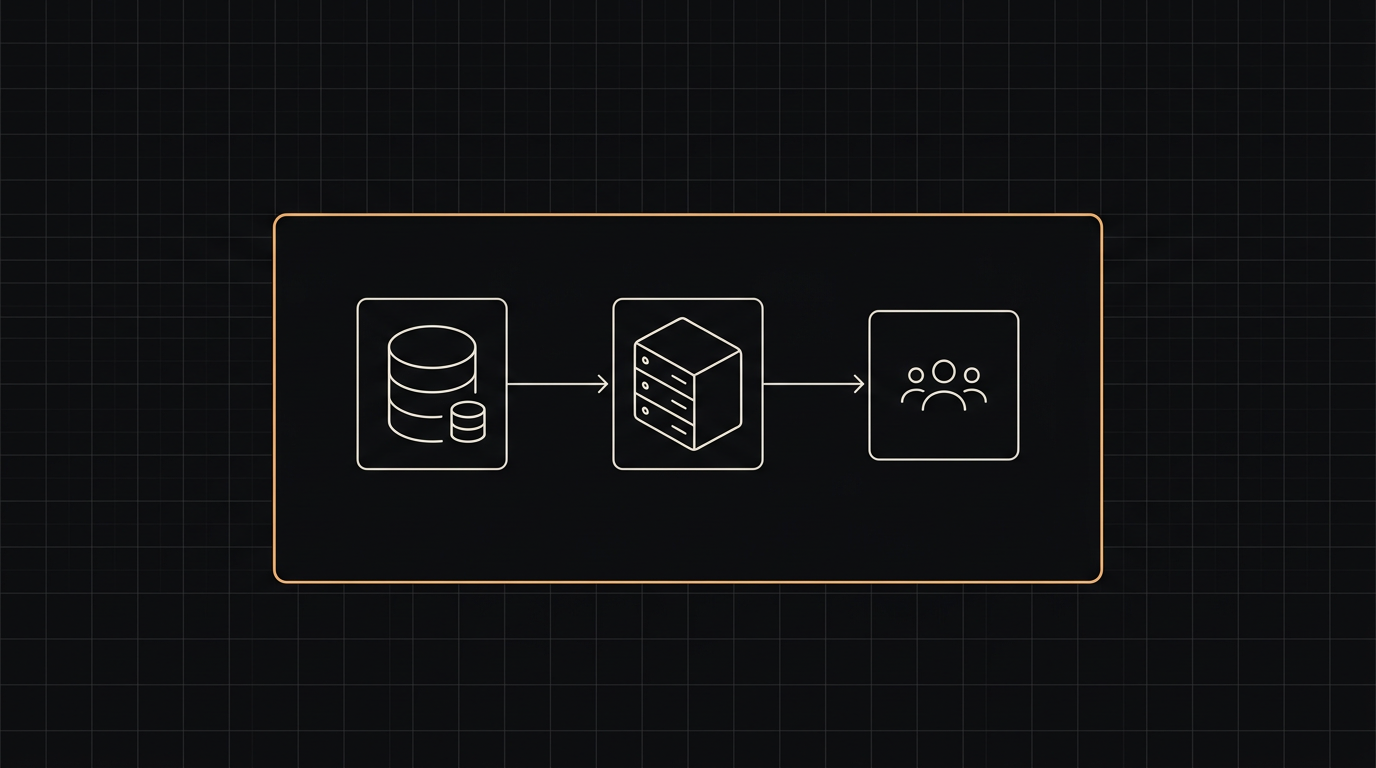
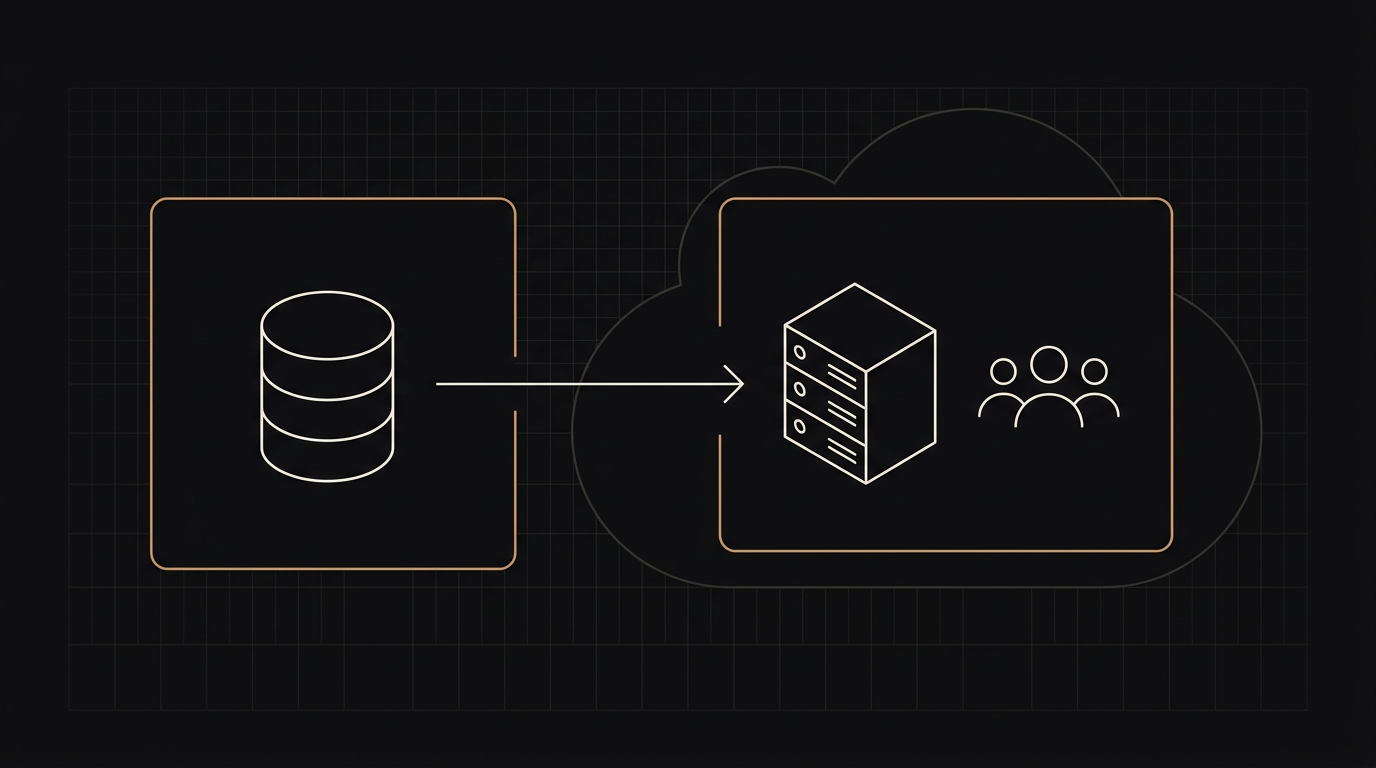
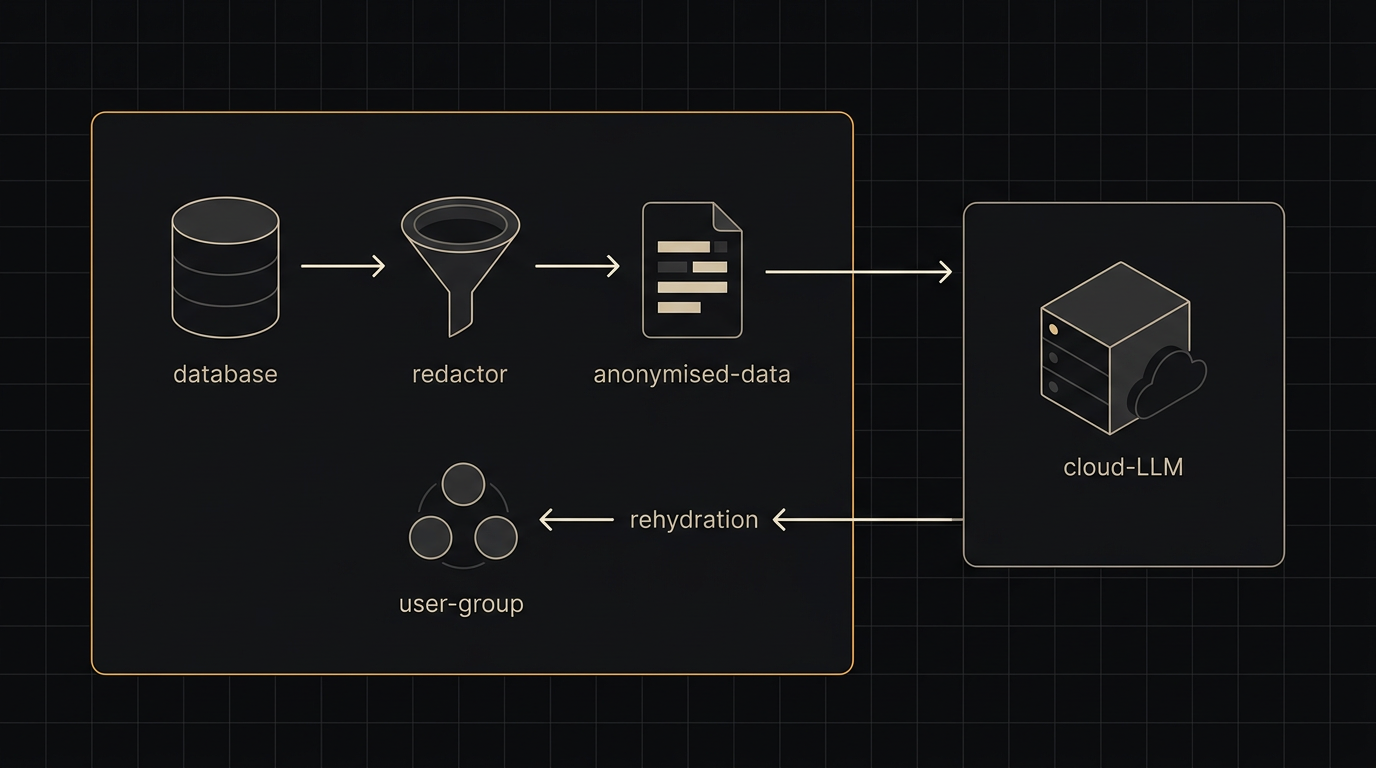
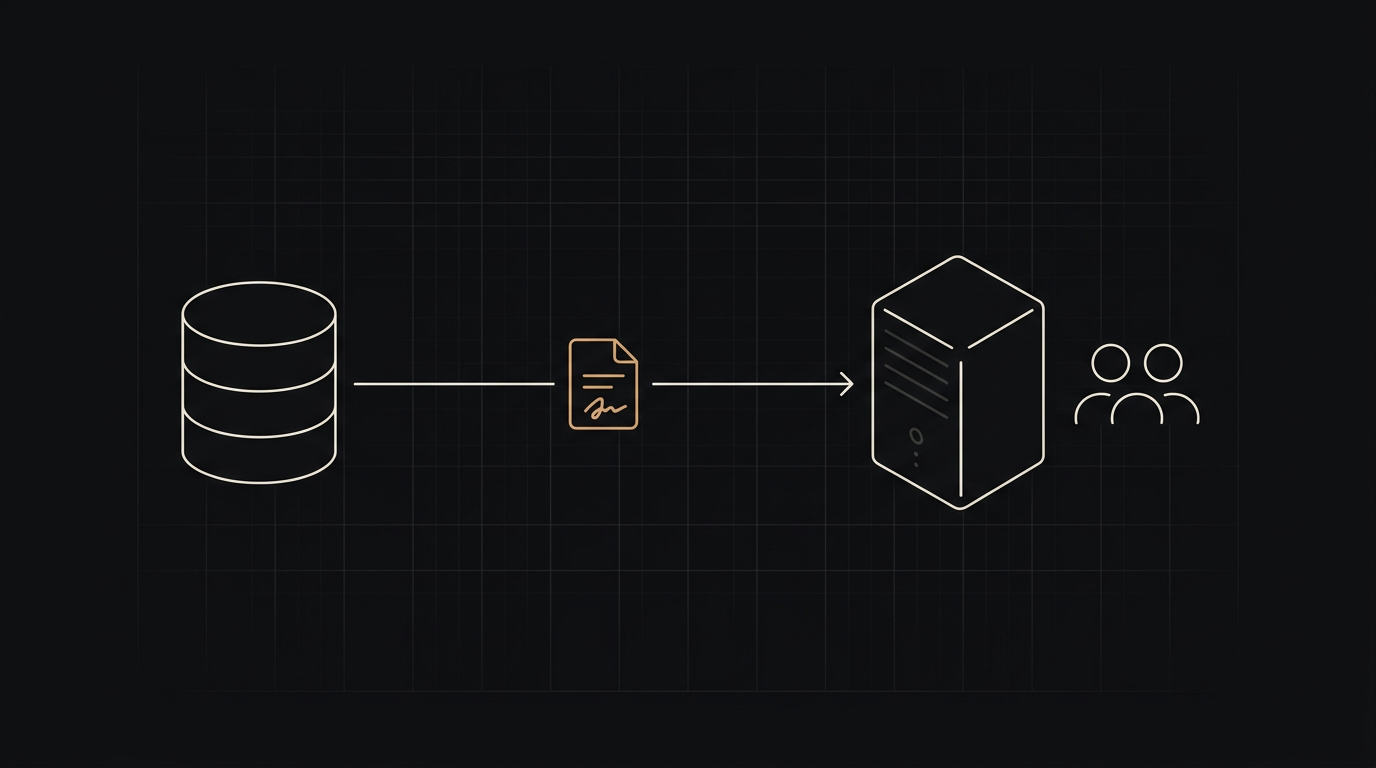
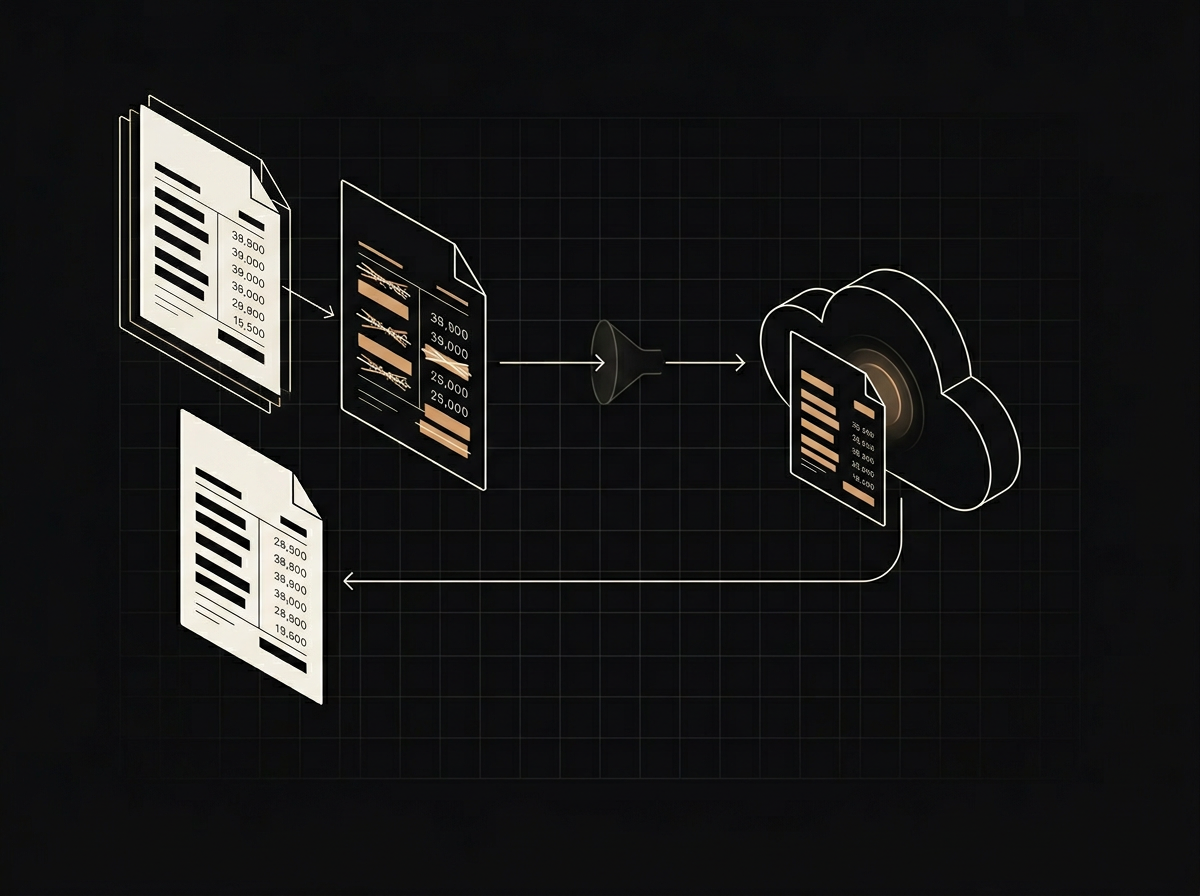
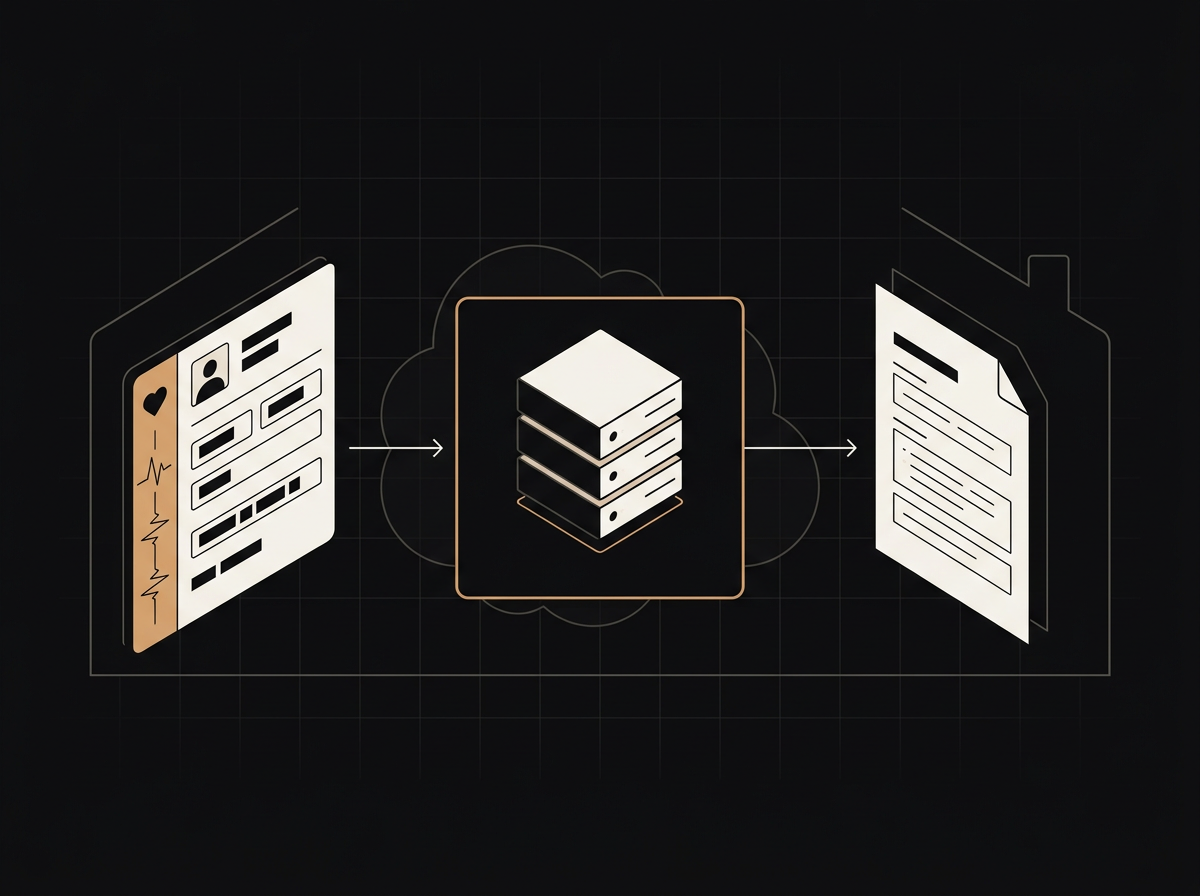
Locally hosted models, private cloud deployments, redaction pipelines, and zero-retention contracts. We design the right balance for regulated work and ship it end to end.
NDA-first scoping
PDPA & GDPR aware
Vendor-agnostic